
总部位于杭州的人工智能企业 DeepSeek 于 2025 年 12 月 1 日正式对外宣布,推出了两款全新的实验性人工智能模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。此次发布,使这家开源开发者直接与那些专有的旗舰模型展开竞争,因为它在效率方面树立了新的行业标准,并在特定领域实现了性能上的比肩。DeepSeek 方面强调,该平台集成了先进的推理能力与自主任务执行功能,这标志着其架构实现了重大飞跃,有力证明了开源系统在面对硅谷领先的闭源模型时,依然能保持强劲的竞争力。
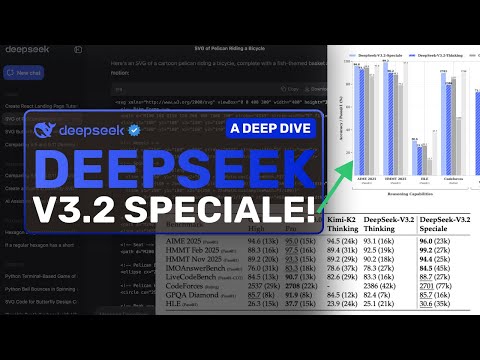
驱动此次效率提升的核心技术突破在于 DeepSeek 稀疏注意力(DSA) 机制。这项架构创新显著降低了处理长上下文信息时所需的计算复杂度,从而使得模型能够在保持快速推理速度的同时,大幅削减计算资源消耗。作为基础迭代的 DeepSeek-V3.2 版本,它不仅采用了 DSA 架构,更是在 V3.1 版本引入的工具调用能力基础上进行了增强。新版本支持调用外部工具,例如代码执行器、计算器以及搜索引擎,并通过“思维链”(thought)和“无思维链”(no-thought)两种操作模式,为用户提供了极大的灵活性。该模型在处理如 SWE-bench Verified 这类现实世界的编程挑战时表现出色,并且在社区的竞争性评估中获得了高度评价,确立了其在平衡通用工作负载方面的高性能地位。
与标准版形成差异化定位的是专业版本 DeepSeek-V3.2-Speciale,该模型专为应对复杂的数学计算和需要多步骤推理的深度挑战而精心设计。DeepSeek 声称,在特定的推理评估任务中,Speciale 版本的性能指标已能与谷歌的 Gemini-3 Pro 相媲美。更值得关注的是,该公司报告称,在模拟 2025 年国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)等全球顶尖赛事的基准数据集上,DeepSeek-V3.2-Speciale 成功达到了“黄金级别”的性能。目前,对计算资源需求较高的 DeepSeek-V3.2-Speciale 访问权限仅限于一个临时的 API 端点,开放至 2025 年 12 月 15 日,这预示着一个受控的部署阶段。而标准 V3.2 模型则已通过申请和网页界面即时开放使用。人工智能领域这种加速发展的态势清晰地表明,开源框架正在复杂应用领域迅速追赶并迎头赶上专有系统。
DeepSeek 此次的发布策略,特别是对 DSA 技术的推广,无疑是对当前人工智能生态的一次有力冲击。通过提供高性能且计算效率更高的开源选项,DeepSeek 正在推动整个行业的创新步伐。开源社区的参与者现在拥有了更强大的工具来构建下一代应用,这对于打破少数科技巨头的技术垄断具有深远意义。这种开放与竞争的态势,预示着未来 AI 技术的普及化和民主化将迈出坚实的一步。


