
L'azienda di intelligenza artificiale con sede a Hangzhou, DeepSeek, ha annunciato il 1° dicembre 2025 il lancio di due nuovi modelli sperimentali di IA: DeepSeek-V3.2 e DeepSeek-V3.2-Speciale. Questa introduzione pone lo sviluppatore open-source in diretta competizione con i prodotti di punta proprietari, stabilendo parametri inediti per l'efficienza e raggiungendo la parità competitiva in ambiti specifici. DeepSeek sostiene che l'integrazione di capacità di ragionamento avanzate con l'esecuzione autonoma di compiti costituisca un progresso architetturale significativo per la loro piattaforma, dimostrando che i sistemi open-source rimangono estremamente competitivi rispetto ai modelli closed-source leader provenienti dalla Silicon Valley.
Il cuore della svolta tecnologica che alimenta questa efficienza risiede nel meccanismo di DeepSeek Sparse Attention (DSA). Questa innovazione architetturale riduce la complessità computazionale tipicamente associata all'elaborazione di contesti estesi. Di conseguenza, il modello riesce a mantenere velocità di inferenza rapide abbassando sensibilmente i costi computazionali. La versione principale, DeepSeek-V3.2, sfrutta questa architettura DSA e si basa sulla funzionalità di utilizzo di strumenti introdotta con la V3.1. Questa nuova iterazione supporta l'impiego di strumenti esterni, inclusi esecutori di codice, calcolatrici e motori di ricerca, offrendo flessibilità attraverso modalità operative sia con 'pensiero' che senza.
Il modello standard V3.2 mostra prestazioni notevoli nelle sfide di codifica del mondo reale, come quelle verificate da SWE-bench Verified. Inoltre, è valutato positivamente dalla comunità in contesti competitivi, posizionandosi saldamente nella fascia ad alte prestazioni per carichi di lavoro generali bilanciati. È chiaro che DeepSeek sta puntando a colmare il divario che spesso separa le soluzioni aperte da quelle proprietarie in termini di applicabilità pratica.
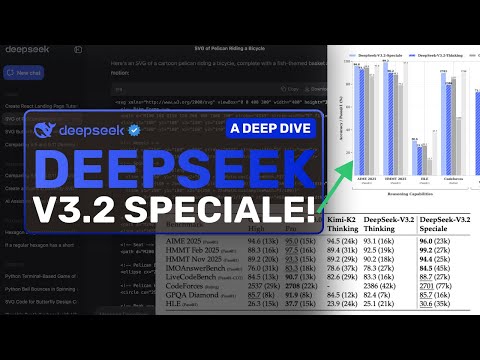
La variante specializzata, denominata DeepSeek-V3.2-Speciale, è stata invece ingegnerizzata per raggiungere prestazioni di picco nei calcoli matematici complessi e nelle sfide di ragionamento multi-step prolungate. L'azienda dichiara che questa versione Speciale eguaglia le metriche di performance di Gemini-3 Pro di Google in specifiche valutazioni di ragionamento. Non è un risultato da poco, considerando la reputazione del modello di Google.
Inoltre, l'azienda ha riportato che DeepSeek-V3.2-Speciale ha raggiunto una performance di livello oro su dataset di benchmark che simulano le edizioni 2025 di prestigiose competizioni globali. Tra queste spiccano l'Olimpiade Internazionale della Matematica (IMO) e l'Olimpiade Internazionale dell'Informatica (IOI). Questo livello di eccellenza in compiti così rigorosi è un segnale forte della maturità raggiunta dal modello.
L'accesso al modello ad alta intensità computazionale DeepSeek-V3.2-Speciale è attualmente circoscritto a un endpoint API temporaneo fino al 15 dicembre 2025. Questo suggerisce una fase di rilascio controllata, un approccio cauto tipico quando si introducono capacità così avanzate. Al contrario, il modello standard V3.2 è immediatamente disponibile tramite richiesta di applicazione e interfaccia web. Questo ritmo accelerato nello sviluppo dell'IA segnala chiaramente che i framework open-source stanno rapidamente diventando funzionalmente competitivi con i sistemi proprietari anche nei domini più esigenti.


