
Штучний інтелект-компанія DeepSeek, що базується в Ханчжоу, 1 грудня 2025 року оголосила про випуск двох нових експериментальних моделей штучного інтелекту: DeepSeek-V3.2 та DeepSeek-V3.2-Speciale. Цей запуск ставить розробника з відкритим вихідним кодом у пряму конкуренцію з пропрієтарними флагманами, встановлюючи нові еталони ефективності та досягаючи паритету в окремих сферах. DeepSeek стверджує, що інтеграція вдосконалених можливостей міркування з автономним виконанням завдань є значним архітектурним проривом для їхньої платформи, доводячи, що системи з відкритим кодом залишаються надзвичайно конкурентоспроможними порівняно з провідними закритими моделями із Кремнієвої долини.
Ключовим технологічним досягненням, що лежить в основі цієї ефективності, є механізм DeepSeek Sparse Attention (DSA). Ця архітектурна інновація суттєво знижує обчислювальну складність, яка зазвичай пов'язана з обробкою довгих контекстів. Це дозволяє моделі підтримувати високу швидкість висновку, одночасно значно зменшуючи обчислювальні витрати. Основна ітерація, DeepSeek-V3.2, використовує цю архітектуру DSA та розвиває функціональність використання інструментів, запроваджену у версії V3.1.
Ця нова версія підтримує залучення зовнішніх інструментів, таких як виконавці коду, калькулятори та пошукові системи. Вона пропонує гнучкість завдяки двом режимам роботи: «з думкою» та «без думки». Модель демонструє вражаючі результати у реальних завданнях з кодування, зокрема на SWE-bench Verified, і високо оцінюється спільнотою у змагальних середовищах. Це закріплює її позиції у високоефективному сегменті для збалансованих загальних робочих навантажень.
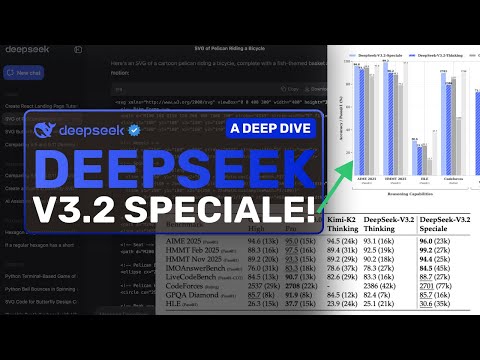
Спеціалізований варіант, DeepSeek-V3.2-Speciale, розроблений для досягнення максимальної продуктивності у складних математичних розрахунках та багатоетапних завданнях на міркування. DeepSeek заявляє, що ця версія Speciale демонструє показники продуктивності, еквівалентні Google Gemini-3 Pro у певних оцінках міркування. Це справді вагома заява, що свідчить про серйозну конкуренцію на ринку.
Крім того, компанія повідомляє, що DeepSeek-V3.2-Speciale досягла золотого рівня продуктивності на еталонних наборах даних, що імітують ітерації 2025 року престижних світових змагань. До них належать Міжнародна математична олімпіада (IMO) та Міжнародна олімпіада з інформатики (IOI). Це підтверджує, що модель здатна вирішувати завдання на рівні найкращих людських талантів.
Доступ до високообчислювальної моделі DeepSeek-V3.2-Speciale наразі обмежений через тимчасову API-кінцеву точку до 15 грудня 2025 року. Це вказує на фазу контрольованого розгортання. Натомість стандартна модель V3.2 одразу доступна для завантаження через заявку та веб-інтерфейс. Такий стрімкий темп розвитку ШІ сигналізує про те, що фреймворки з відкритим кодом швидко набувають функціональної конкурентоспроможності з пропрієтарними системами у складних доменах, що є добрим знаком для всієї індустрії.


